
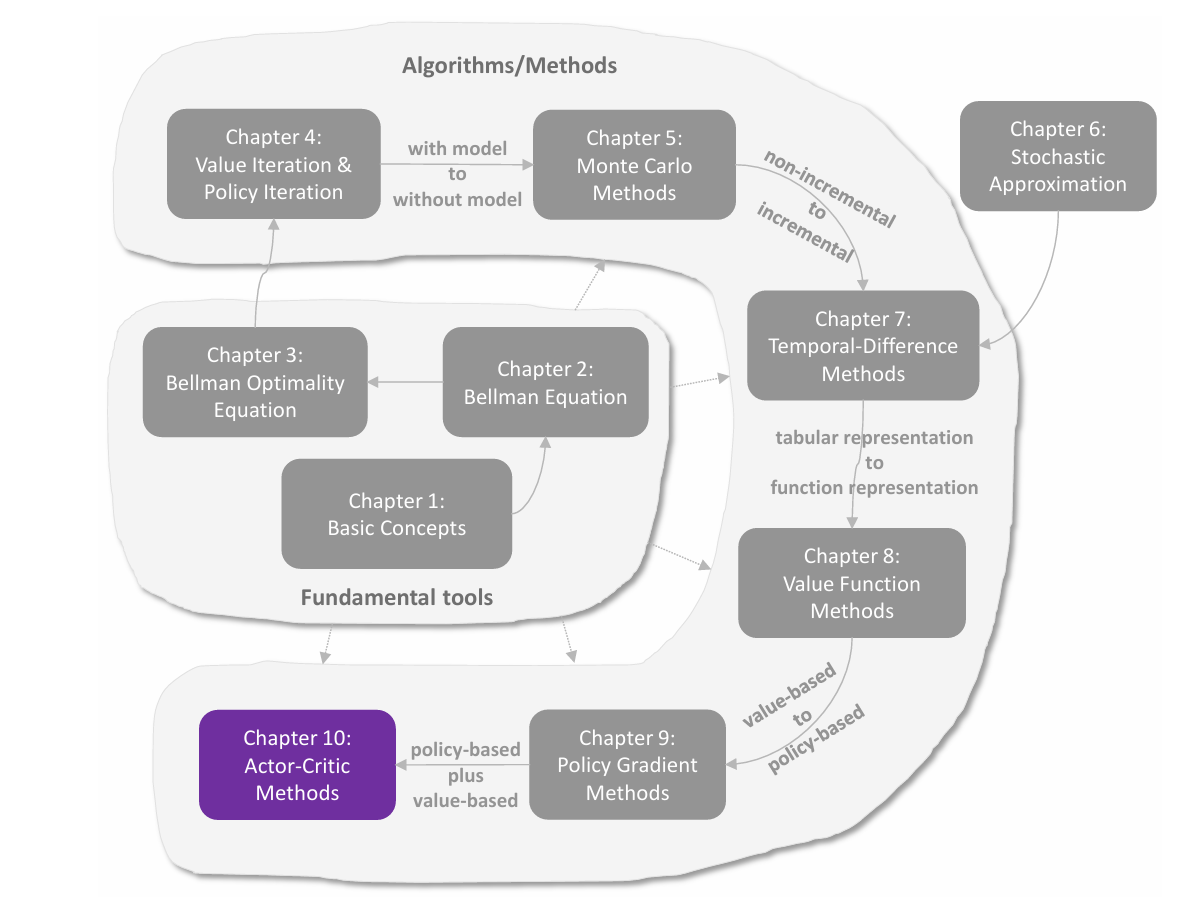
C9 Actor-Critic 方法
Actor-Critic方法是强化学习中一类重要的算法,它融合了**策略梯度(Policy Gradient)和价值估计(Value Estimation)**两种思想。其名称源于算法内部的两大组件: Actor:负责策略更新,决定如何选择动作。它通过最大化目标函数 J(θ)J(\theta)J(θ) 来更新策略参数 θ\thetaθ。 Critic:负责价值评估,评价 Actor 所采取动作的好坏。它通过学习价值函数来估计状态或动作的价值。 Actor-Critic 方法本质上是策略梯度算法的扩展——当策略梯度算法中 qt(st,at)q_t(s_t,a_t)qt(st,at) 使用TD学习而非 MC 估计时,便得到了 Actor-Critic 方法。 QAC:最简单的 Actor-Critic 算法 Q Actor-Critic(QAC) 是最基础的Actor-Critic算法,它通过将策略梯度与 Sarsa 价值估计结合,直观地展示了Actor-Critic的核心思想。 从 policy gradient 到...
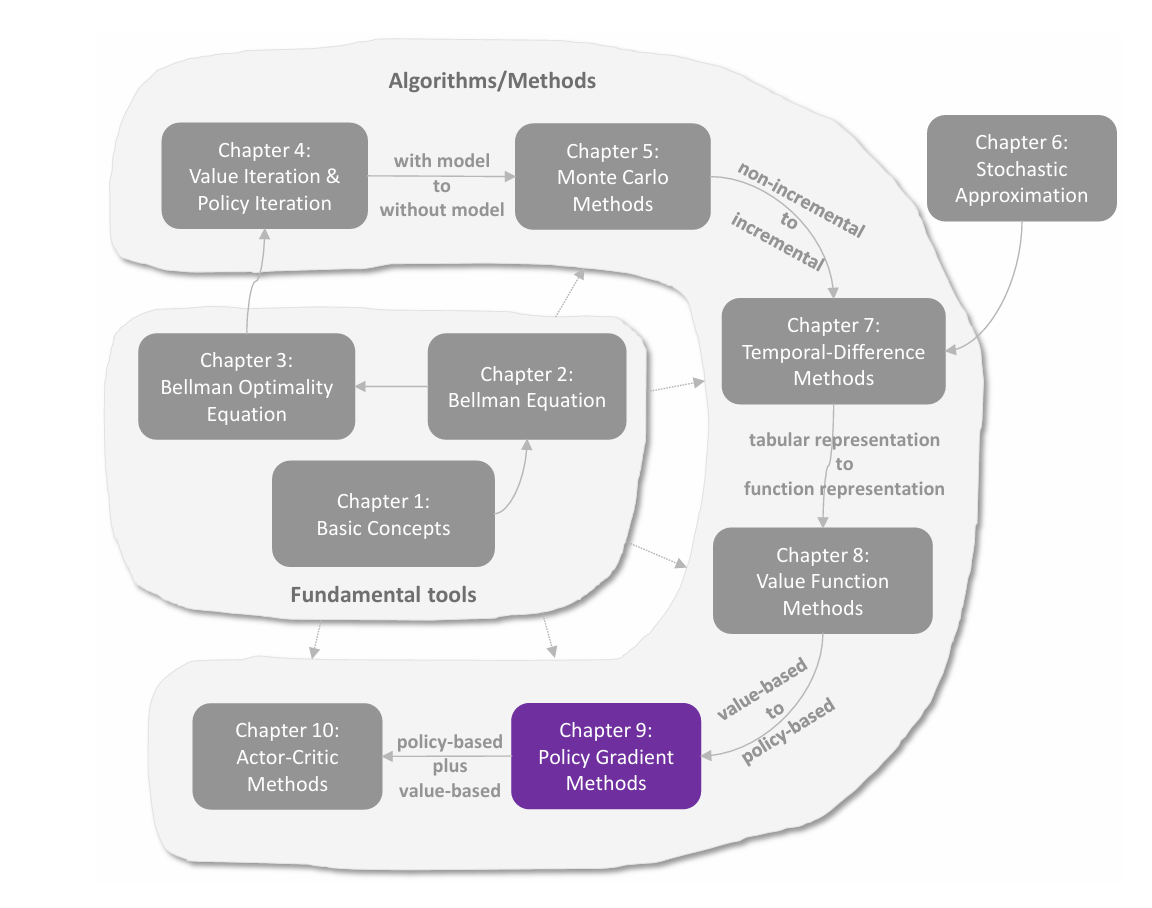
C8 策略梯度方法
策略表示:从表格到函数 值函数近似的思想不只可以用于表示 state/action values,还可以应用于策略表示。在本章之前,策略都是通过表格的形式呈现: 在本章中,策略可以被参数化的函数表示为 π(a∣s,θ)\pi(a|s,\theta)π(a∣s,θ),其中 θ∈Rm\theta\in\mathbb{R}^{m}θ∈Rm 是参数向量。函数也可以写为 πθ(a∣s)\pi_{\theta}(a|s)πθ(a∣s),πθ(a,s)\pi_{\theta}(a,s)πθ(a,s) 或 π(a,s,θ)\pi(a,s,\theta)π(a,s,θ)。当策略通过函数表示时,最优策略可以直接通过优化某些特定的 scalar metrics 来获取,这样的方法称为 policy gradient(策略梯度)。例如,设 J(θ)J(\theta)J(θ) 是一个 scalar metric,最优策略可以通过梯度上升优化目标函数得到: θt+1=θt+α∇θJ(θt),\theta_{t+1}=\theta_t+\alpha\nabla_\theta...
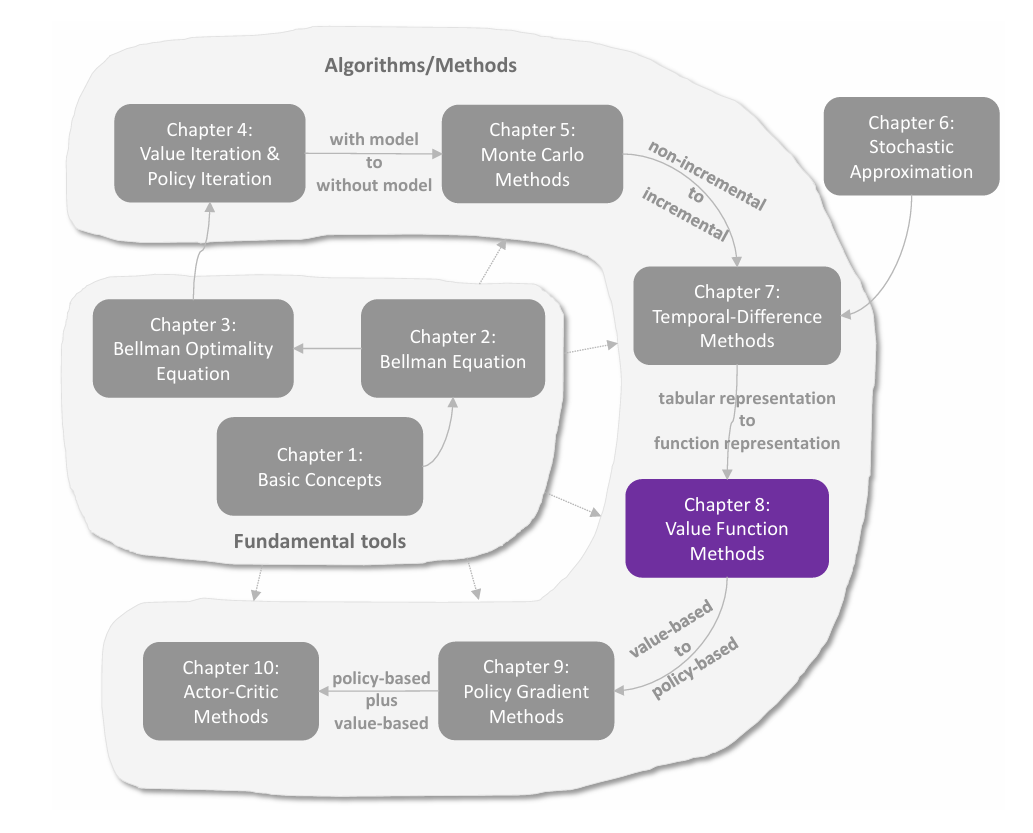
C7 值函数方法
值表示:从表格到函数 在前面各章中,状态值和动作值都是用表格(tabular)来表示的。表格方法直观易懂,但在处理大规模状态空间或动作空间时效率低下。本章引入值函数方法(value function method),使用函数来近似表示状态值或动作值,这已成为表示价值的标准方法,也是将人工神经网络引入强化学习作为函数近似器的切入点。 基本思想 假设有 nnn 个状态 {si}i=1n\{s_i\}_{i=1}^n{si}i=1n,其真实状态值为 {vπ(si)}i=1n\{v_\pi(s_i)\}_{i=1}^n{vπ(si)}i=1n。 若采用表格方法,估计值 {v^(si)}i=1n\{\hat{v}(s_i)\}_{i=1}^n{v^(si)}i=1n 存储在一个表中,可以直接读取或修改: 如果采用函数近似,则用函数 v^(s,w)\hat{v}(s,w)v^(s,w) 来近似 vπ(s)v_\pi(s)vπ(s),其中 www 是参数向量,v^(s,w)\hat{v}(s,w)v^(s,w) 有时被简写为...
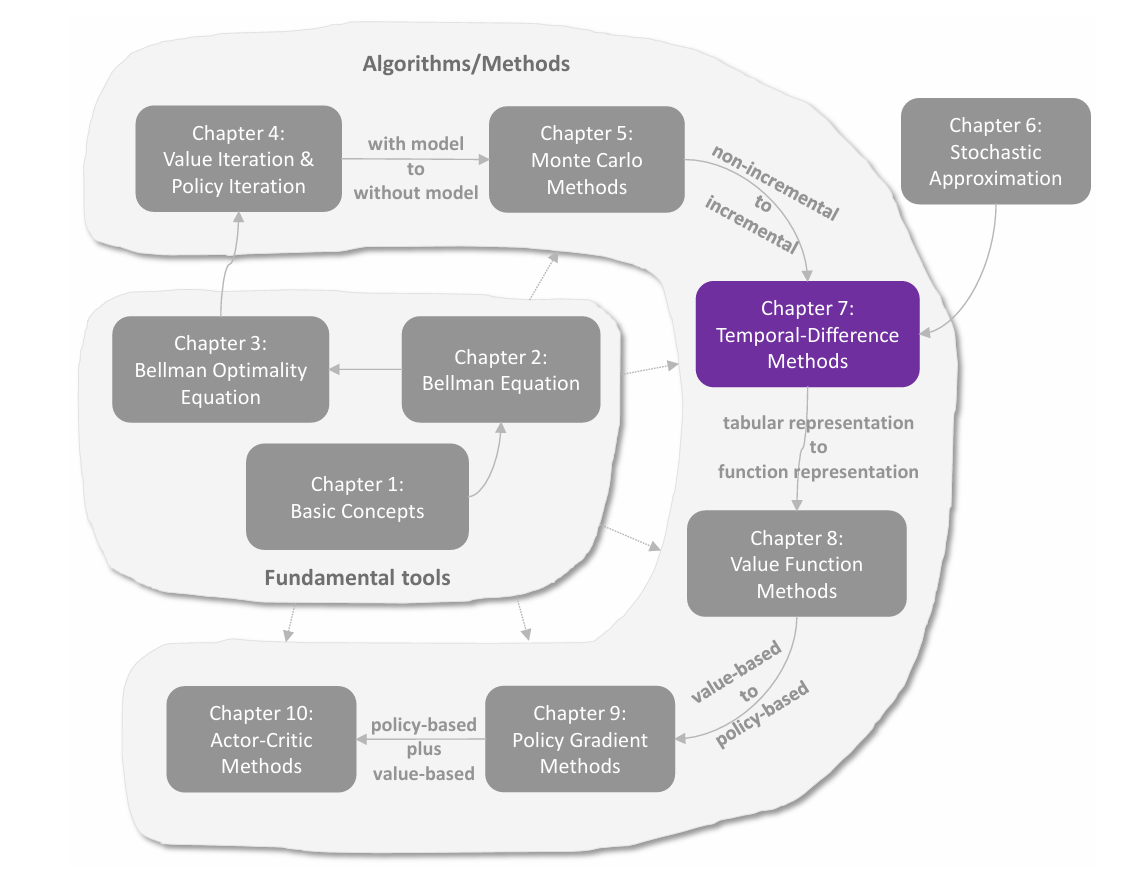
C6 时序差分方法
temporal-difference(TD,时序差分)方法是强化学习中用于价值估计的一类广泛的算法。其与 MC 方法一样,也是 model-free 的方法,但相比 MC 方法的优势是以 **incremental(增量式)**的形式进行。TD 算法的数学本质是 stochastic approximation(随机近似)。 入门:一种估计 state values 的 TD learning 方法 方法内容 在上一节介绍 RM 算法的基础上,考虑使用 RM 算法去估计 state values。 给定一个策略 π\piπ,目的是估计所有的 vπ(s)v_{\pi}(s)vπ(s)。假设遵循策略 π\piπ,采集到的经验样本为 (s0,r1,s1,…,st,rt+1,st+1,… )(s_0,r_1,s_1,\dots,s_t,r_{t+1},s_{t+1},\dots)(s0,r1,s1,…,st,rt+1,st+1,…),其中 ttt 表示时间步,则下面的 TD 算法可以利用这些样本来估计 state...
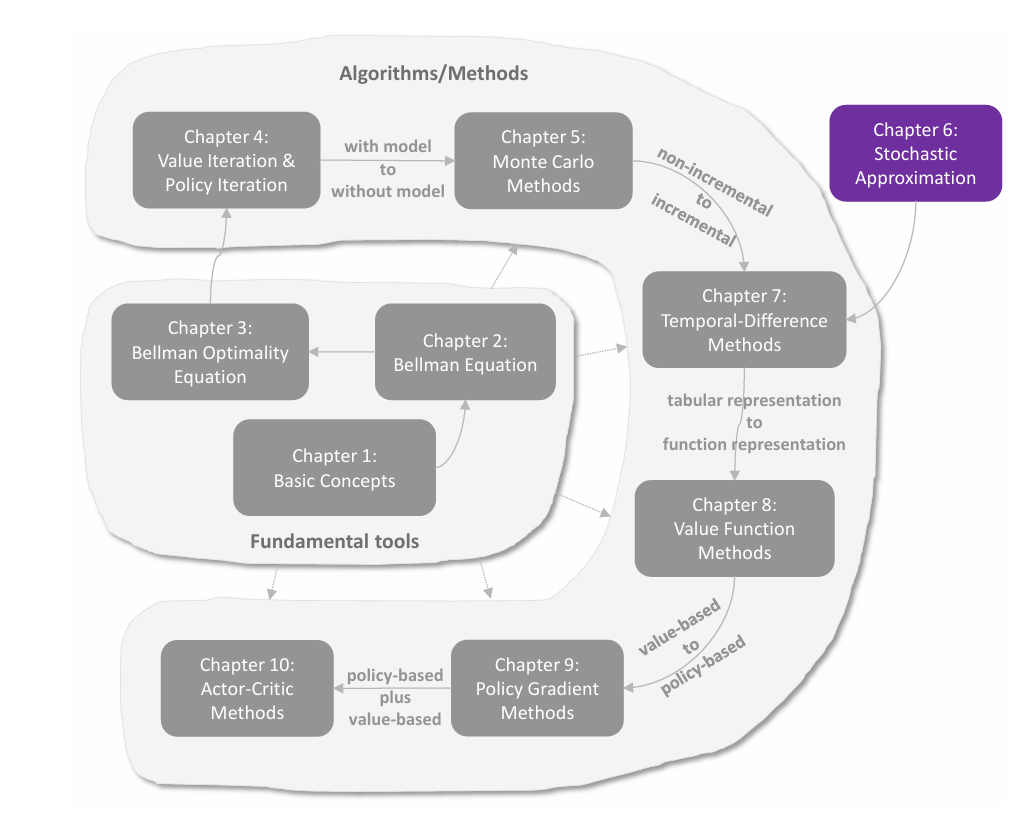
C4 随机近似
均值估计:从 non-incremental 到 incremental 在强化学习和机器学习中,incremental(增量式)指的是一类逐步更新的方法:每获得一条新数据(或一个完整片段),就立即用它来修正当前估计,而不是等到收集全部数据后再一次性计算。 考虑一个随机变量 XXX,取值集合为 X\mathcal{X}X。若要估计 E[X]\mathbb{E}\left[X\right]E[X],在 model-free 的情况下,可以采样一系列 i.i.d. 的样本 {xi}i=1n\{x_i\}_{i=1}^n{xi}i=1n,则 E[X]\mathbb{E}\left[X\right]E[X] 可以被这些样本的均值估计 E[X]≈xˉ=1n∑i=1nxi\mathbb{E}\left[X\right]\approx\bar{x}=\frac{1}{n}\sum_{i=1}^n x_i E[X]≈xˉ=n1i=1∑nxi 这实际上就是蒙特卡洛法。根据大数定律可知当 n→∞n\to\inftyn→∞ 时...
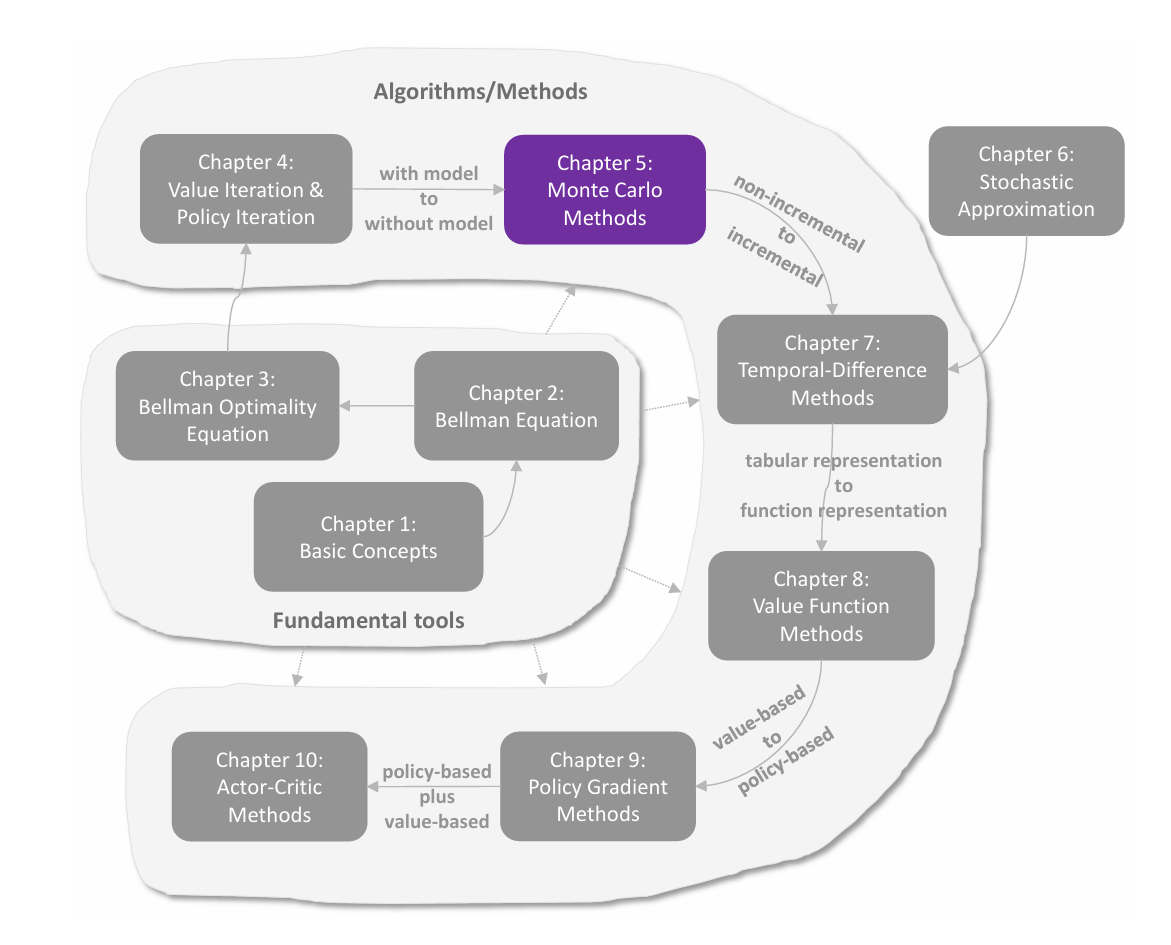
C4 蒙特卡洛方法
蒙特卡洛法 蒙特卡洛法(Monte Carlo method,MC)是一类通过随机采样来近似求解数值问题的计算方法。其核心思想是:利用大量**独立同分布(independently identically distribution,i.i.d.)**的随机样本,通过统计量(如均值、频率)来估计原本难以直接计算的数学量(如积分、期望、最优化解等)。 这里主要讨论 MC 方法在估计期望的应用,因为估计一个 state value 或 action value 的本质就是期望估计问题。 考虑一个随机变量 XXX,其所有可能的取值集合为 X\mathcal{X}X。若要估计 XXX 的均值(期望)E[X]\mathbb{E}\left[X\right]E[X],可以采用两种方法: 基于模型的方法(model-based):这里的模型指随机变量 XXX 的分布。若 XXX 的分布已知,可以直接求出 XXX 的期望 E[X]={∑xp(x),X 离 散∫xp(x)dx,X 连 续\mathbb {E} [ X ] = \left\{ \begin{array}{l l} \sum x...
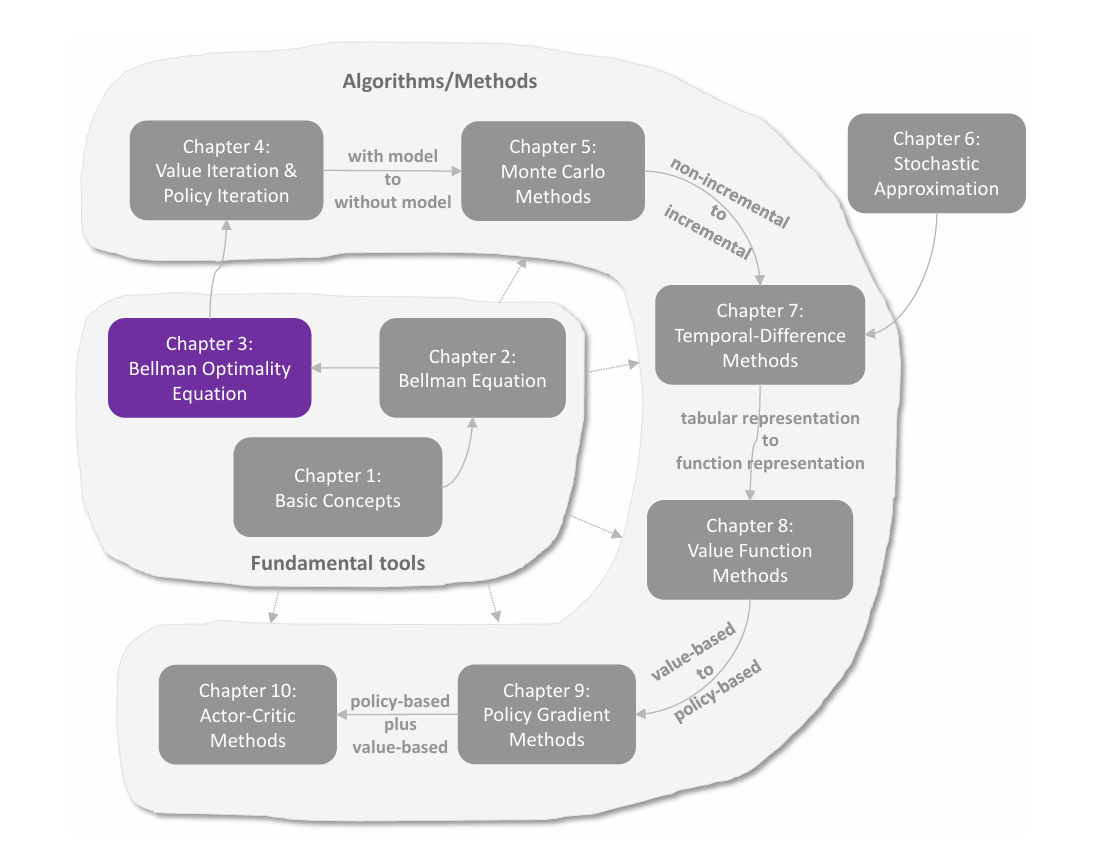
C3 贝尔曼最优公式
Policy 改进 设 γ=0.9\gamma=0.9γ=0.9,则可以解出上图策略下的 state values 为 vπ(s1)=8,vπ(s2)=vπ(s3)=vπ(s4)=10v_{\pi}(s_1)=8,\\v_{\pi}(s_2)=v_{\pi}(s_3)=v_{\pi}(s_4)=10 vπ(s1)=8,vπ(s2)=vπ(s3)=vπ(s4)=10 计算 s1s_1s1 的 action values: qπ(s1,a1)=−1+γvπ(s1)=6.2,qπ(s1,a2)=−1+γvπ(s2)=8,qπ(s1,a3)=0+γvπ(s3)=9,qπ(s1,a4)=−1+γvπ(s1)=6.2,qπ(s1,a5)=0+γvπ(s1)=7.2.\begin{array}{l} q _ {\pi} \left(s _ {1}, a _ {1}\right) = - 1 + \gamma v _ {\pi} \left(s _ {1}\right) = 6. 2, \\ q _ {\pi} \left(s _ {1}, a _ {2}\right) =...
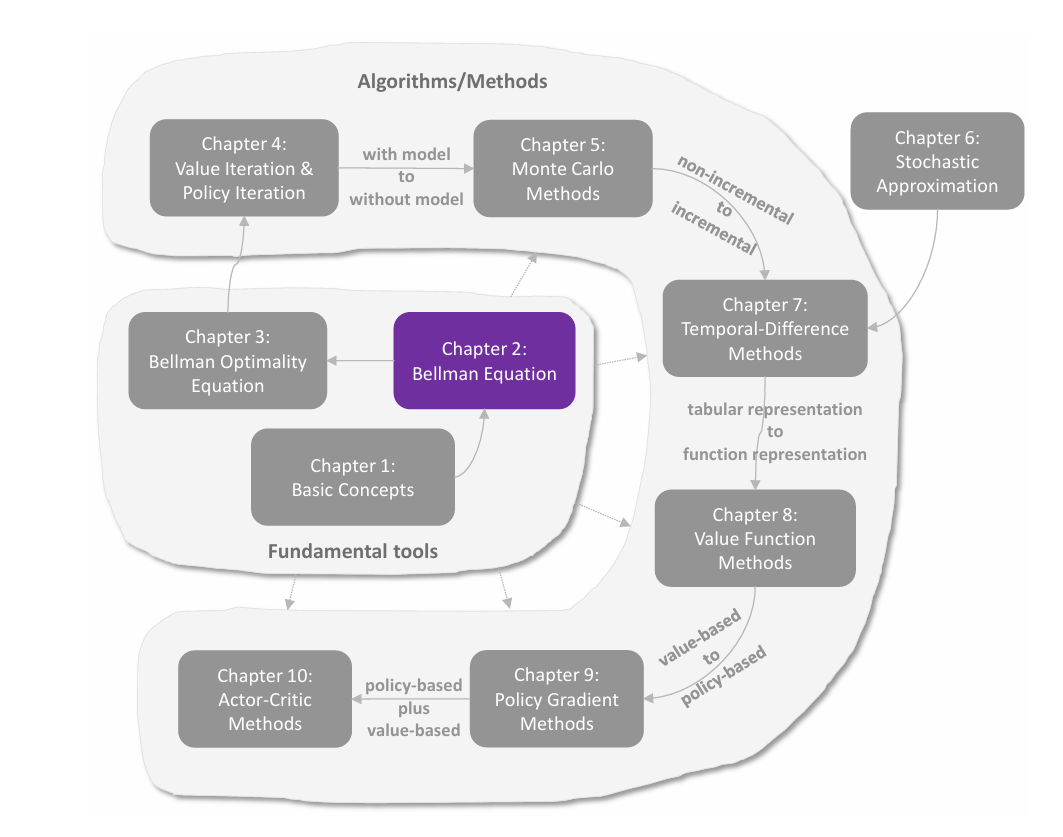
C2 贝尔曼公式
关于 Return 之前说过 return 能够衡量 trajectory 的收益,这里用一个例子来具体说明。 从状态 s1s_1s1 出发到 s4s_4s4,上图从左至右的回报依次是: return1=0+γ1+γ21+γ31+⋯=γ(1+γ+γ2+… )=γ1−γreturn2=−1+γ1+γ21+γ31+⋯=−1+γ(1+γ+γ2+… )=−1+γ1−γreturn3=0.5(γ1−γ)+0.5(−1+γ1−γ)=−0.5+γ1−γ\begin{align} \text{return}_1...
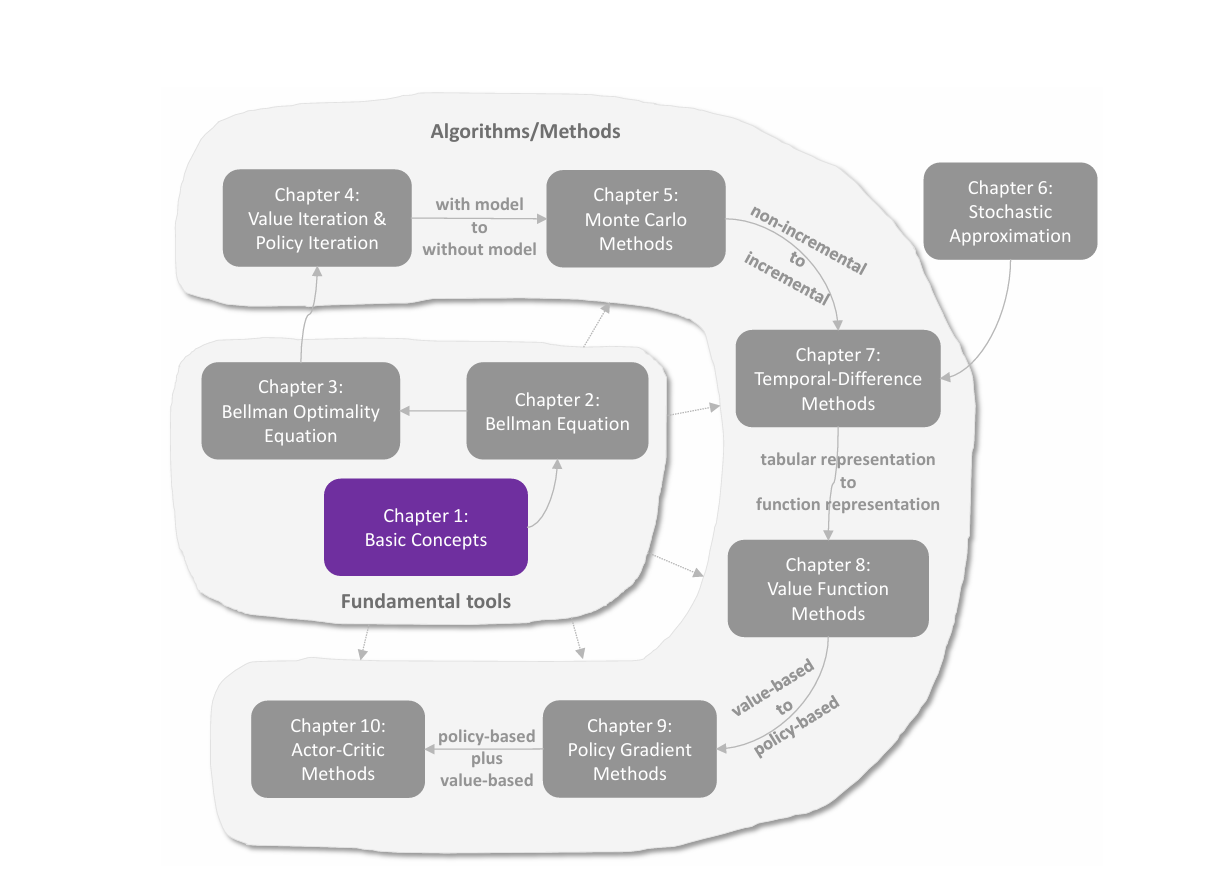
C1 概念&MDP
基本概念 状态,动作,奖励 State(状态):环境在某一时刻的描述,包含智能体决策所需的所有相关信息。所有 state 构成的集合为 state space,记为 S\mathcal{S}S。 Action(动作):智能体在某个状态 sss 下可以采取的操作,记为 A(s)\mathcal{A}(s)A(s),其中 s∈Ss\in\mathcal{S}s∈S。动作会改变环境状态。 Reward(奖励):智能体执行动作后,环境返回的即时标量信号,用于评价该动作的好坏。智能体的目标是最大化累积奖励(回报)。在状态 sss 下采取 aaa 动作所得到的 reward 记为 R(s,a)\mathcal{R}(s,a)R(s,a),其中 s∈S,a∈A(s)s\in\mathcal{S},a\in\mathcal{A}(s)s∈S,a∈A(s)。 以机器人 grid world 为例,每个方格对应一个 state;在每个方格可以采取 5 个 action,分别为向上、向右、向下、向左和不动 5 个移动情况;在每个 state 下采取每一种 action...
![[论文阅读] RMOT](/images/RMOT.png)
[论文阅读] RMOT
概览 **时间:**CVPR2023 贡献:提出指代多目标跟踪任务(referring multi-object tracking, RMOT),并基于 KITTI 构建了数据集 Refer-KITTI 用于推进工作,同时基于 Transformer 开发了一个模型架构 TransRMOT 以在线方式解决 RMOT 任务。 研究背景 将 NLP 融入场景感知的指代理解逐渐发展,但是现有的数据集和基准测试无法在多个指代目标和时间状态变化的情况下提供准确的评估: 现有数据集的每个表述通常对应一个目标,而现实世界往往指代多个对象。 给定的表述可能只描述了视频指代任务的部分帧,导致对应关系不准确。例如对于指代"the car which is turning",标注可能只存在于车辆“正在转弯”的那几帧;而当车转完弯进入直行状态时,标注就应该停止了。 模型架构 TransRMOT...