
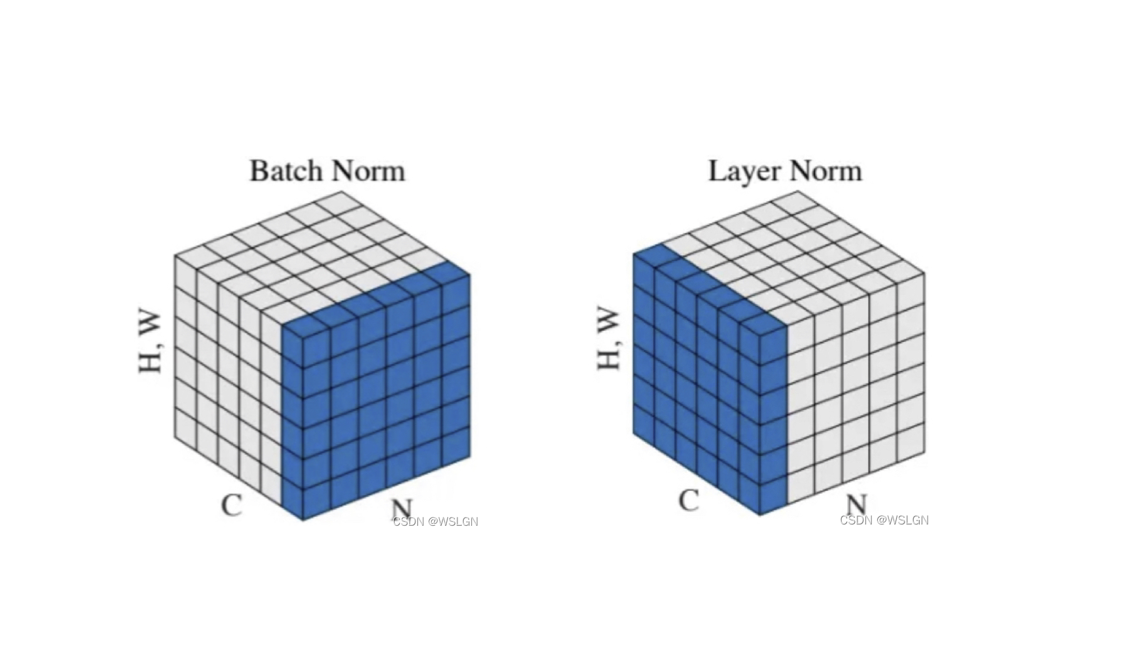
协变量偏移,BatchNorm 和 LayerNorm
协变量偏移 协变量 协变量(Covariate)是指除自变量外,会影响因变量的其他变量。 例如,假如需要通过函数 y^=Wx\hat{y}=Wxy^=Wx 去回归给定的数据 (x∗,y∗)(x^*,y^*)(x∗,y∗),那么 y^\hat{y}y^ 为因变量,WWW 为自变量(在拟合过程中不断更新),而 xxx 就是协变量。 协变量偏移 协变量偏移(Covariate Shift)是数据集偏移(Dataset Shift)的一种,指的是在模型训练和应用时,输入数据(特征)的分布发生了变化,但输出标签的分布保持不变。一般分为两种: 内部协变量偏移:在训练过程中,深度网络隐藏层的前一层参数更新,会改变其输出,从而直接改变后一层的输入分布,导致深度网络内部任一隐藏层的输入数据分布随着训练迭代而发生动态变化。这使得每一层都需要不断适应一个“漂移”的输入分布,导致训练不稳定、收敛慢、需要更小的学习率。 外部协变量偏移:训练集的输入分布与测试集的输入分布不一致。这会导致模型在训练集上表现良好,但在测试集上表现不佳。 BatchNorm 与...
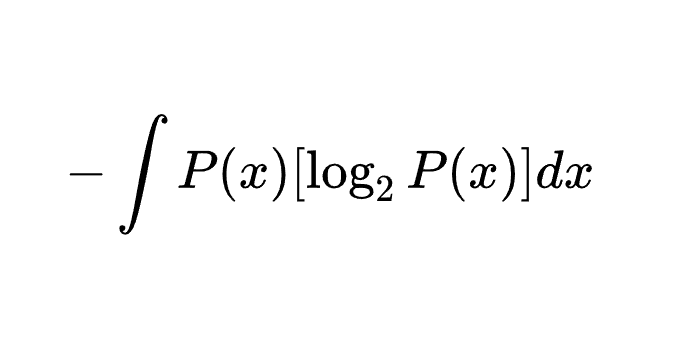
熵、交叉熵,KL 散度
熵 信息量 信息量是对信息的度量,我们接受到的信息量和具体发生的事情有关。 信息的大小和随机事件的概率负相关。概率越小的事情若发生了产生的信息量越大,因为它排除了别的很多的可能性,例如今天下冰雹;而概率越大的事情产生的信息量越小,例如太阳从东边升起并不会带来什么信息。 假设有不相关事件 XXX 和 YYY,若两个事件同时发生,其概率为 P(X,Y)=P(X)∗P(Y)P(X, Y)=P(X)*P(Y)P(X,Y)=P(X)∗P(Y),产生的信息量为 h(X,Y)=h(X)+h(Y)h(X, Y)=h(X)+h(Y)h(X,Y)=h(X)+h(Y),由此可见信息量 h(X)h(X)h(X) 与发生概率 P(X)P(X)P(X) 对数相关。 综上两条性质,可以定义信息量: h(X)=−log2P(X)h(X)=-\log_{2}P(X) h(X)=−log2P(X) 底数为 2 这是因为只是遵循信息论的普遍传统,使用 2...
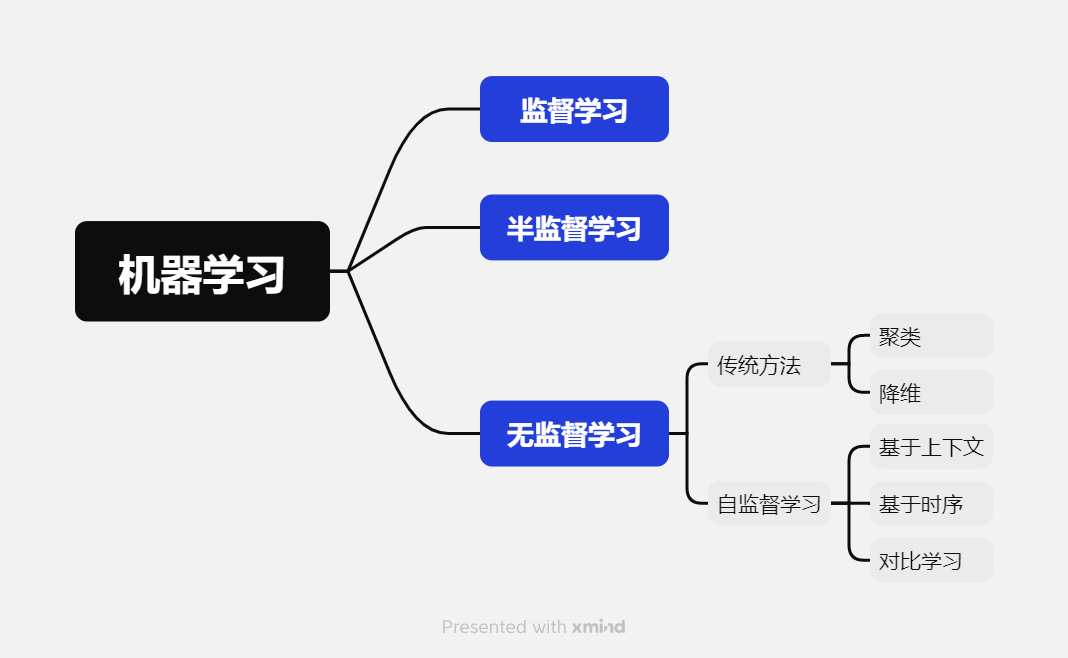
机器学习的学习方法
监督、无监督与半监督 机器学习中基本的学习方法有:监督学习(Supervised learning)、半监督学习(Semi-supervised learning)和无监督学习(Unsupervised learning)。他们最大的区别就是模型在训练时需要人工标注的标签信息,监督学习利用大量的标注数据来训练模型,使模型最终学习到输入和输出标签之间的相关性;半监督学习利用少量有标签的数据和大量无标签的数据来训练网络;而无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类。 监督学习 监督学习就是已知输入数据(Input data)和输出数据(Annotations),通过训练一个模型(Model)来建立输入和输出之间的映射。在回归和分类任务中应用广泛。常用的监督学习方法包括:决策树、SVM、神经网络、线性回归和逻辑回归等。 无监督学习 无监督学习是已知输入数据(Input...

OS_Challenge_SWAP 实现报告
前言 SWAP 挑战性任务主要关于内存管理、进程调度与外设访问,基本只涉及内核的改动,要求对以上的知识有充足的认识与深刻的理解。代码改动总体上不算多(相较于 SHELL 挑战性任务),但根据自己的感受以及别人的描述是 SWAP 任务的思考量相对来说比较大, SHELL 代码量大但是是挑战性任务中思考量最小的一个。我自己花了大概 3 天的时间实现指导书上的所有操作 + 过编译(仅仅只是过编译,很多实现因为理解不到位都有错误),然后花了 3 天的时间 debug。 我在实现的过程中,pmap.c 改动的内容是最多的,因为其涉及 swap_out、swap_in 以及 TLB 重填逻辑等有关 SWAP 核心机制的实现。ide.c 和 ide.h 是我新增的文件,因为当前 MOS 中对外设的访问是通过文件系统实现的(Lab5\mathrm{Lab5}Lab5 内容),其属于用户进程,并不方便内核去使用,且关键问题在于:Lab5\mathrm{Lab5}Lab5 实现的文件系统是对主 IDE 控制器进行访问的,而 SWAP 挂载的磁盘...

OS LAB5 文件系统
思考题 Thinking 5.1 如果通过 kseg0 读写设备,那么对于设备的写入会缓存到 Cache 中。这是 一种错误的行为,在实际编写代码的时候这么做会引发不可预知的问题。请思考:这么做 这会引发什么问题?对于不同种类的设备(如我们提到的串口设备和 IDE 磁盘)的操作会有差异吗?可以从缓存的性质和缓存更新的策略来考虑。 当外部设备自身更新数据时,如果此时 CPU 写入外设的数据还只在缓存中,则缓存的那部分数据就只能在外设自身更新后再写入外设(只有缓存块将要被新进入的数据取代时,缓存数据才会被写入内存),这样就会发生错误的行为。 对于串口这类实时交互设备,问题表现为明显的 I/O 延迟和丢失。对于IDE 磁盘这类块设备,问题可能导致命令执行失败、磁盘状态混乱,最严重的是静默数据损坏,危害性极大且难以排查。 Thinking 5.2 查找代码中的相关定义,试回答一个磁盘块中最多能存储多少个文件控制 块?一个目录下最多能有多少个文件?我们的文件系统支持的单个文件最大为多大? 在 user/include/fs.h 中,磁盘块大小 BLOCK_SIZE 定义为...

OS LAB4 系统调用与fork
思考题 Thinking 4.1 思考并回答下面的问题: •内核在保存现场的时候是如何避免破坏通用寄存器的? •系统陷入内核调用后可以直接从当时的$a0-$a3 参数寄存器中得到用户调用 msyscall 留下的信息吗? •我们是怎么做到让 sys 开头的函数“认为”我们提供了和用户调用 msyscall 时同样的参数的? •内核处理系统调用的过程对 Trapframe 做了哪些更改?这种修改对应的用户态的变化是什么? 内核使用宏函数 SAVE_ALL 来保存现场,在该函数的代码实现里,只使用了 k0 和 k1 两个通用寄存器来进行操作,从而保证其他通用寄存器的值都不会被改变。 可以。因为内核在陷入内核、保存现场的过程中,寄存器$a0-$a3 中的值都没有被破坏。 用户在调用 msyscall 时,传入的参数会被保存在$a0-$a3 寄存器和堆栈中。当陷入内核时,$a0-$a3 寄存器不会被破坏,而且用户栈中的内容会被原封不动地被拷贝到内核栈中。因此,sys_* 函数可以从寄存器和内核栈获得"用户调用 msyscall...

OS LAB3 进程与异常
思考题 Thinking 3.1 请结合 MOS 中的页目录自映射应用解释代码中 e->env_pgdir[PDX(UVPT)] = PADDR(e->env_pgdir) | PTE_V 的含义。 一个页目录项映射一个含有 1K 个页表项的 4KB 页表,每一个页表映射一个 4MB 大小的虚拟地址空间。由于页目录映射的 4MB 空间就是二级页表结构所在的 4MB 空间,而用户二级页表结构存储在虚拟地址空间中的 UVPT 至 ULIM 处的 4MB 空间 ,因此页目录相当于第 PDX(UVPT)(取高 10 位)个页表,也就位于第 PDX(UVPT) 个页目录项,其物理地址 PADDR(e->env_pgdir) 存储在这个页目录项中。 Thinking 3.2 elf_load_seg 以函数指针的形式,接受外部自定义的回调函数 map_page。请你找到与之相关的 data 这一参数在此处的来源,并思考它的作用。没有这个参数可不可以?为什么? int elf_load_seg(Elf32_Phdr *ph, const void *bin,...

OS LAB2 内存管理
思考题 Thinking 2.1 请根据上述说明,回答问题:在编写的 C 程序中,指针变量中存储的地址被视为虚拟地址,还是物理地址?MIPS 汇编程序中 lw 和 sw 指令使用的地址被视为虚拟地址,还是物理地址? 虚拟地址;虚拟地址。 Thinking 2.2 请思考下述两个问题: • 从可重用性的角度,阐述用宏来实现链表的好处。 • 查看实验环境中的/usr/include/sys/queue.h,了解其中单向链表与循环链表的实现,比较它们与本实验中使用的双向链表,分析三者在插入与删除操作上的性能差异。 **Q1:**通过宏定义对链表的操作进行封装,实现了代码复用,减少了代码量的同时便于代码的维护。 Q2: /usr/include/sys/queue.h 的单向链表只能获取每一项的后一项,因此在插入与删除时都需要对链表进行遍历,时间复杂度为 O(n)O(n)O(n); /usr/include/sys/queue.h 的循环链表既实现了双向链表,又维护了头尾指针,插入与删除时可以根据链表项直接获取其位置进行操作,并获取其前后项,时间复杂度为...

OS LAB1 内核、启动和printf
思考题 Thinking 1.1 在阅读附录中的编译链接详解以及本章内容后,尝试分别使用实验环境中的原生 x86 工具链(gcc、ld、readelf、objdump 等)和 MIPS 交叉编译工具链(带有 mips-linux-gnu- 前缀,如 mips-linux-gnu-gcc、mips-linux-gnu-ld),重复其中的编译和解析过程,观察相应的结果,并解释其中向 objdump 传入的参数的含义。 不同工具链的比较 使用 gcc -E hello.c > ori_prep.txt 和 mips-linux-gnu-gcc -E hello.c > cross_prep.txt,获取原生 x86 工具链和 MIPS 交叉编译工具链对于 hello.c 的预处理结果,并通过命令 diff ori_prep.txt cross_prep.txt -y 比较两个预处理结果的不同。可以看到不同工具链使用的工具路径不同、对某些变量的定义不同等。 工具路径不同: 1234567891011# 0 "hello.c" ...

OO Unit2 多线程
架构设计 黄色部分为第一次作业的类,红色部分为第二次作业新增类,紫色部分为第三次作业新增类。 架构迭代 第一次作业 整体采用了生产者-消费者的设计模式。考虑到第一次作业指定了乘客请求的电梯,我并没有设置调度器线程,而是输入线程 inputThread 读取到乘客请求后直接放入每个电梯各自的乘客请求处理队列 processingQueue。电梯运行采用 LOOKLOOKLOOK 策略,电梯线程 elevatorThread 每执行完一个动作后从自己的 processingQueue 中取出一个乘客请求,并结合自身的信息发送给策略类 Strategy,获取下一动作 advice 并执行。 第二次作业 第二次作业新增了临时调度请求,并取消了乘客请求指定电梯,即需要调度给某部电梯来运送乘客。因此在第二次作业中,我新增了全局的请求队列 requestQueue,并由调度器线程 dispatchThread 来将请求分配给某部电梯,放入其请求处理队列 processingQueue,随后电梯线程 elevatorThread...